~ 6 min read
Automatic Spotify Playlist Creation with Pipedream and Supabase
Every week I create a new version of my site mixes.it based on new DJ mixes that have been released. It generates Spotify playlists for every new mix it finds based on data scraped from the web and builds a new static version of the site. I’ve been running it for a little over a year now and it always makes me happy when a new playlist arrives.
Previously I’ve written on how I structure my Astro project to make use of new data. Here I’ll be explaining how I collect the data with Pipedream and Supabase to create Spotify Playlists from it.
This post was written as part of Supabase’s launch week - go check it out for all their announcements.
Introduction
Pipedream is the tool I use for connecting APIs. It allows me to have a single service without the complexities of managing authentication with different APIs, scheduling tasks and executing code. Supabase is an open source Firebase alternative which crucially for this project provides my Postgres database and REST API. Their hosted offering allows me to get a remote instance which works nicely with Pipedream.
I wanted this to be a low touch project, since I can’t dedicate much time to it. I also didn’t want to have an infrastructure to maintain or to pay for, so it’s nice that I can use a free hosted offering of both Pipedream and Supabase to run it all.
Scraping the Data
Pipedream organises projects using steps and workflows. Each workflow comprises of a number of different steps and requires a trigger step to begin. For this project I have 4 different workflows in total of which I’ll focus on a few key areas.
Most of the triggers I currently execute are based on a simple cron scheduler. You can run any workflow at any time whilst you’re testing it out whilst deciding on a version of the workflow to deploy.
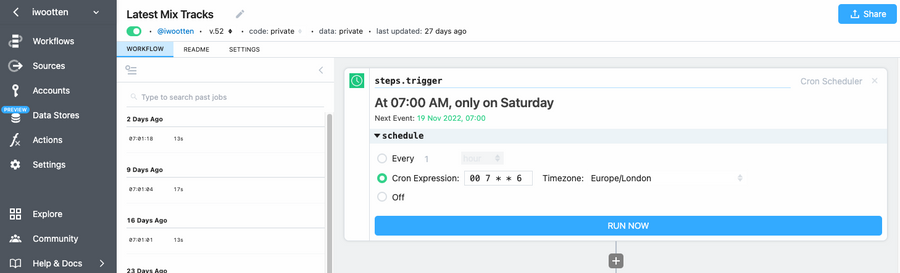
Steps can execute any JavaScript or Python code or be based on existing steps which are shared by the community and Pipedream team. To scrape a collection of mixes I use cheerio and the Supabase js client.
Lets start by looking at the workflow step to collect new mixes. Firstly I use Supabase to look up mixes I’ve already indexed from previous weeks so I can ignore them.
You can see here I’ve used environment variables to set the credentials for Supabase to keep them out of the step. Keeping variables out of the step allows you to share common steps between workflows.
import { createClient } from '@supabase/supabase-js';
const supabase = createClient(process.env.SUPABASE_URL, process.env.SUPABASE_KEY);
async function scrape(url) {
let { data: old_mixes, error: select_error } = await supabase
.from('mixes')
.select('url');
let existing_urls = [];
if (old_mixes !== null) {
existing_urls = old_mixes.map(x => x.url)
}
}
return await scrape(params.url);Following this I can use cheerio to lookup data from the URL I’m interested in and extract what I need. cheerio has a very simple jQuery like interface for traversing and manipulating the data found, but doesn’t render anything so it’s great for my purposes. I pull out the url, artist, title and description of all new mixes trimming any whitespace out of the way. I also filter out all the mixes I’ve already indexed.
import fetch from 'node-fetch';
import cheerio from 'cheerio';
...
const res = await fetch(url);
const html = await res.text();
let $ = cheerio.load(html);
let mixes = [];
let artist = $('.br-masthead__title a').text().trim();
$('.programme__body').each(function(index, element){
let element_url = $(element).find('h2 a').attr('href');
if (!existing_urls.includes(element_url)) {
mixes.push({
'url': element_url,
'title': $(element).find('span.programme__title').text().trim(),
'description': $(element).find('.programme__synopsis span').text().trim(),
'artist': artist
})
}
})
...Then it’s a simple case of inserting all the new mixes I know back to Supabase.
...
const { data, error: insert_error } = await supabase
.from('mixes')
.insert(mixes, {upsert: true})
return mixes;
...This collects all the mixes, but then I also need to index tracks from each of the mixes. I have a separate Pipedream workflow to fetch that data in much the same way as the mixes and store it in a separate table mixes_tracks.
At this point I should be able to see the data within the interface for my hosted Supabase instance.
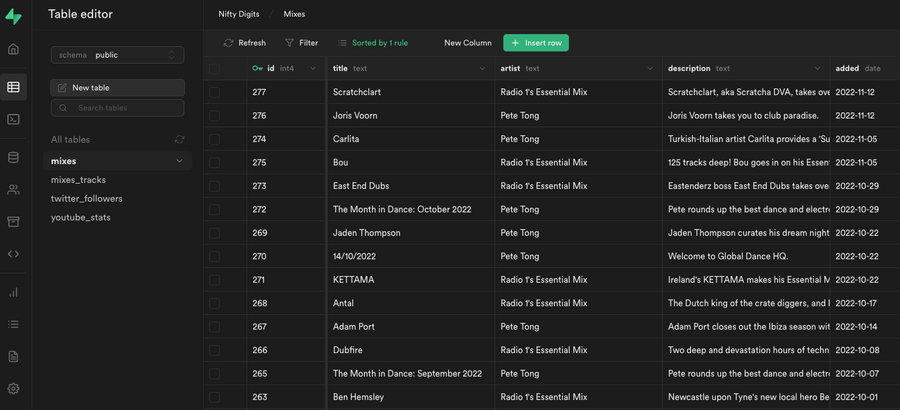
Creating the Playlists
Next I create the Spotify playlists. If I hadn’t used pipedream here I’d need to authenticate with Spotify and refresh credentials when they expired myself. That’s reduced to a few clicks within Pipedream and allows me to sleep more peacefully.
Firstly, I have a step that looks up any new data found by joining mixes and mixes_tracks.
const { createClient } = require('@supabase/supabase-js');
const supabase = createClient(process.env.SUPABASE_URL, process.env.SUPABASE_KEY);
let { data: mixes_to_fetch, error } = await supabase
.from('mixes')
.select(`
*,
mixes_tracks (
position,
artistname,
trackname
)
`)
.is('spotify_playlist', null)
.order('added', { ascending: false });Using axios I can create a new playlist using Spotify’s API before looking up every new track I’ve found using a search query like so:
let search_config = {
url: 'https://api.spotify.com/v1/search',
headers: {
Authorization: `Bearer ${auths.spotify.oauth_access_token}`,
},
params: {}
}
for (const mix_track of mixes_tracks) {
search_config.params = {
'q': `${mix_track.artistname} - ${mix_track.trackname}`,
'type': 'track'
}
try {
let results = await require("@pipedreamhq/platform").axios(this, search_config);
if (results.tracks.total > 0) {
tracks.push(results.tracks.items[0].uri)
}
} catch (error) {
console.log(error.response)
}
console.log(mix_track.artistname)
}You can see this approach makes a number of assumptions, blindly picking the first result found in Spotify’s library which in some cases is the wrong track. It also will just suppress any errors, waiting for me to come and sort it out.
Following updating both the playlist with tracks and the mixes table with the new playlist id, I then trigger a Netlify build of the entire site. Read my previous post if you’re interested in how the Astro project I use for this is setup and built.
Conclusion
This combination of Supabase and Pipedream has worked out really well for me. It’s allowed me to experiment with different approaches within a very lean setup. It’s also done this at no expense which is particularly good for me since this is a side project.
On occasion there may be an error - perhaps a DJ does a particularly complex mix consisting of over a hundred tracks(!) which results in a timeout on track lookup. The thing I really like is that there’s rarely much debugging since I can log in to either service’s user interface and see errors without having to hunt around too much. I can make adjustments and fire off an instant rebuild with the new data.
Creating static sites like this is obviously a very niche use case, but for something that needs to be updated infrequently I think works very well.